Peppol eDelivery: Do we even need an SML?
2024-02-27 - Jelte JansenA recent topic of discussion in the Peppol community is the function and architecture of the Service Metadata Locator (SML) in the Peppol network. What has, so far, not been considered in that discussion is whether we actually need an SML in the first place.
The SML is the starting point of capability lookups: if you want to send a business document to another participant, you first need to find out whether they can process that particular kind of document, and if they do, where and how to send it.
To find out this information, you query that participant’s Service Metadata Publisher (SMP). But you first need to find the correct SMP for that participant, and that you can do using the SML: with the Service Metadata Locator, you find the Service Metadata Publisher.
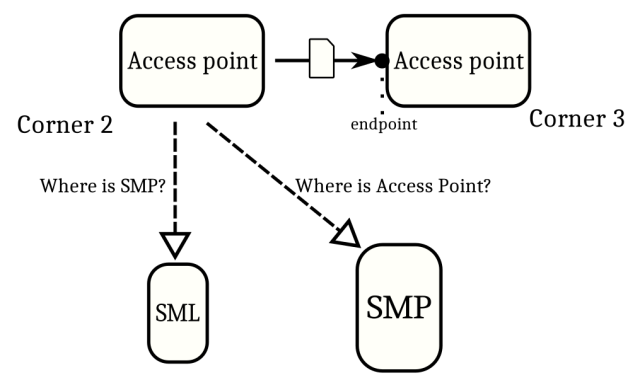
How the SML works
There are currently 2 types of SML in use in eDelivery networks; both are implemented as Domain Name System (DNS) zones.
The first one, as it is used by the Peppol network, published SHA-1 digests of all registered participant identifiers as CNAMES in a central DNS zone. CNAME records can be compared to http redirects, but on a DNS level: the CNAME record tells you under which domain name the SMP of the recipient can be found. There, you query a pre-determined URI to perform the SMP capability lookup.
The second method, based on the BDXL specification, also publishes digests of all registered participants in a central zone, but in this case the algorithms is SHA-256, and it returns NAPTR (Name Authority Pointer) records; these contain a full URI of the SMP. This is still just the ‘base’ URI, but the important difference here is that is allows https requests, where the CNAME approach can only use http.
Those features already make the second approach an improvement over the first, but they both have a significant drawback: all participants are published in a single flat DNS zone.
The problem of a flat DNS zone
While DNS scales pretty well, both horizontally and vertically, having a single flat DNS zone be the starting point of all lookups in an eDelivery network is a single point of failure that could become an issue as the network grows; not just operationally (the larger the zone, the higher the costs to keep it running, and the higher the costs of issues), but also organizationally (the larger the zone, the more support it needs) and potentially even in terms of network sovereignity (some industries, countries, or regions may have issues relying on such a large part of the infrastructure being out of their jurisdiction).
Therefore, people are now talking about all of these: upgrade from CNAME-based lookups to NAPTR-based lookups, where such a central zone should be maintained, and even whether the protocol should be changed to a more hierarchical model, where operational as well as organizational maintenance can be delegated to different parties.
And it was this last topic that made me think:
Do we even need an SML in the first place? Why don’t we just put the relevant CNAME or NAPTR record in our own DNS zones?
It’s always DNS
To get Ionite’s website, browsers do a DNS lookup for the IP address of ionite.net. To send an email to anyone at ionite, the mail server does a DNS lookup for Ionite’s mail server. Why not do a direct DNS lookup for Peppol as well, in the ionite.net DNS zone?
It does seem that capability lookups are still useful, or rather, that the information published by an SMP is too much to maintain directly in DNS, so let’s say we add a new DNS record type that simply points to the relevant SMP, just as the centralized approach currently does.
For instance, peppol.ionite.net would be a NAPTR record that points to https://sml.ion-smp.net, where the transport and document type details for Ionite could be found.
Instead of looking up Ionite on the Peppol network by way of our Chamber of Commerce number, people would have to look up ionite by the domain name ‘peppol.ionite.net’, or maybe even simply ‘ionite.net’, just like when you visit a website or send an email.
Considerations of direct DNS lookups instead of an SML
Of course, this approach would require some fundamental changes: ‘domain names’ would have to be added to the list of allowed addressing schemes, a new lookup protocol would have to be defined, and to do it cleanly, either a label or DNS record type would have to be registered at IANA, probably by way of an IETF RFC.
There are, compared to the centralized approach, other drawbacks as well: organizations would have to maintain their Peppol DNS records correctly –already often an issue with both web and mail records– as their Peppol Service Providers can no longer do this for them. And since they are now likely to be maintained by different parties: there needs to be synchronization between the maintainer of the DNS zone(s) and that of the SMP, to make sure their configurations match.
Perhaps more importantly, participants would have to communicate which domain name is to be used for Peppol transactions (their Peppol Address, as it were) to their business partners that want to send them documents.
That last is probably the largest disadvantage: While it’s not without its own issues, mainly related to organizations or branches that share a common legal registration identifier, automatic discovery would become more difficult. You would, for instance, no longer be able to ‘just’ look up the participants Chamber of Commerce or VAT number to check whether they are connected to the network. You would have to know which domain name they use for Peppol communication.
That said, there are some important advantages here as well: the starting point of capability lookups is now DNS itself; there is no longer a centralized system on top of that.
Another potential advantage is that organizations can now use multiple distinct identifiers: say they use a different Service Provider for processing Orders and Invoices, they could use ‘invoice.peppol.example.com’ for invoicing, and ‘orders.peppol.example.com’ for orders. Or branches of a large organization can use their own e-invoicing solution (‘peppol.mybranch.example.com’) instead of relying on internal routing at a central access point for the entire organization.
And of course, organizations that maintain their own DNS records have full control over their Peppol Identifier, since it is published in their own DNS zone. If they wish to change service providers, they no longer need their current provider to cooperate in the transfer.
Semi-central DNS solutions could still be an option, where service providers would offer a subdomain specific for organizations to register a peppol identifier. This would have its own disadvantages, and reduce some of the advantages mentioned before, but it could be an option for organizations that can’t or don’t want to maintain their own DNS records.
Conclusion
The SML, as currently used in eDelivery networks such as Peppol, is a globally centralized piece of infrastructure that uses the DNS as its publication mechanism. Recently, people have been discussing who should operate this piece of infrastructure, whether the lookup protocol should be upgraded, and even whether it should be redesigned to be more distributed than it currently is. This article proposes that we that a step further, and that we consider using DNS records in the domain names owned by participants themselves to publish the information currently published by the SML.
There are more technical issues to consider than the ones I’ve written about here, and of course there’s several ways that it could be implemented. I’m also quite sure that I’ve missed some advantages and shortcomings of an approach like this, and in the end, the disadvantages may very well outweigh the advantages.
But in theory, it should be possible use the DNS itself as the starting point of capability discovery in an eDelivery network, without resorting to a single global centralized DNS zone. So, while we are discussing which form the SML should have, I do think we should consider this:
Perhaps we don’t need one at all.
Want to join the discussion? Comment on Mastodon, LinkedIn, or join the Peppol Community.